Large language models (LLMs) have shown great success in many NLP tasks, including question answering, text generation, and more. However, the accuracy, consistency, and explainability of LLMs still hinder their application in many real-world scenarios. To address these problems, researchers have proposed numerous methods to enhance these abilities in LLMs. One of the most promising methods involves combining LLMs with knowledge graphs (KGs), a high-quality, structured knowledge source known for its reasonable explainability. Conversely, LLMs can also be used to improve the quality of knowledge graphs. In this blog, we will discuss the mutual reinforcement between LLMs and KGs.
Basic Concepts
Knowledge Graph
In simple terms, a knowledge graph is a way of organizing and representing information in a structured format. It consists of a collection of interconnected nodes and edges, where each node represents a specific entity or concept, and each edge represents a relationship between those entities or concepts.
Think of a knowledge graph as a visual representation of knowledge, where entities are represented as nodes (also known as vertices) and relationships between entities are represented as edges (also known as links). For example, in a knowledge graph about movies, nodes could represent actors, directors, movies, and genres, while edges could represent relationships such as “acted in,” “directed,” or “belongs to genre.”
The power of a knowledge graph lies in its ability to capture and represent complex relationships between different entities. It allows you to connect the dots between different pieces of information and provides a framework for understanding how things are related.
Knowledge graphs are commonly used in various applications, such as search engines, recommendation systems, and virtual assistants. The concept of a knowledge graph was initially introduced by Google in 2012. Google’s knowledge graph functions as a knowledge base to augment their search engine’s search results with semantic-search information sourced from a diverse range of origins. To know more about the concepts, advantages, and use cases, please check this blog.
Building a high-quality knowledge graph is a systematic and laborious process. The main steps can be summarized in this repo. To explain more clearly, we will use the following figure to illustrate the process of building a knowledge graph.

As shown in the picture, building a knowledge graph is an intricate process that primarily consists of five stages: Knowledge Collection, Knowledge Integration, Knowledge Storage, Knowledge Computation, and Knowledge Application. It begins with gathering the data, extracting relevant entities and relationships from this data, then integrating the data into a coherent, unified format. This structured data is then stored using appropriate methods for easy retrieval and computational processes. The knowledge graph is finally put into action in applications such as semantic search and question answering. Each of these stages plays a crucial role in the construction of a functional and efficient knowledge graph.
Knowledge Collection is the first step in the process of creating a knowledge graph. This involves a procedure known as Automatic Crawl, a method used for collecting data from various sources like web pages, documents, and databases. The collected data is then processed to extract relevant entities and their relations in a process called Entity Extraction and Relation Extraction. Entities refer to distinct objects, concepts, or individuals like a person, place, event, or an organization, while relations define how these entities interact or are related to each other.
The next phase is Knowledge Integration, which encompasses Entity Linking, Entity Disambiguation, and Entity Alignment. Entity Linking connects entities from the collected data to their corresponding entities in the knowledge graph. Entity Disambiguation, on the other hand, deals with identifying and distinguishing entities with similar or identical names. Entity Alignment is crucial when integrating knowledge from different sources or languages, as it identifies the same real-world entity across different data sources or languages.
Knowledge Storage is the stage where the integrated knowledge is stored for efficient use. This includes ER (Entity-Relationship) Storage, where entities and their relations are stored in a structured manner. Graph Storage involves storing the knowledge graph in a graph database, a storage system optimized for storing and querying graph data. Graph Retrieval and Formal Query are techniques to efficiently fetch the stored data for further processing or answering user queries.
The Knowledge Computation phase involves creating a meaningful representation of the knowledge graph and performing inference tasks. Knowledge Representation is about structuring the knowledge graph in a way that both humans and computers can understand. Knowledge Inference is the process of deducing new knowledge from the existing knowledge graph. Graph Complement, on the other hand, is an operation that fills in missing information in the graph by inferring from the available data.
Finally, the Knowledge Application stage puts the knowledge graph into action. Semantic Search leverages the knowledge graph to provide more accurate and context-aware search results. Knowledge Question Answering (QA) uses the knowledge graph to answer queries by understanding the context, entities, and their relations involved in the query. This stage effectively demonstrates the value of a knowledge graph in enhancing information retrieval and understanding.
In summary, building a knowledge graph is a complex process involving various stages, each with its specific role and importance. The result is a powerful tool that significantly improves our ability to search for, understand, and infer knowledge.
Language Model
Contrasting knowledge graphs, large language models (LLMs) harness neural networks to model knowledge. The GPT series, a transformer-based language model, is among the most renowned LLMs. Let’s delve into the training process of the GPT series.
The GPT series has attained several milestones, with GPT-3, InstructGPT, and ChatGPT being the most noteworthy. Thanks to a vast corpus and unsupervised learning, GPT-3 can generate text that closely resembles human writing. InstructGPT was developed to enhance GPT’s adherence to instructions, utilizing supervised learning with human-labelled context following the instructions, and employs RLHF to generate text that is more contextually appropriate. ChatGPT, conversely, was designed to boost GPT’s conversational capabilities with humans. It employs an approach similar to InstructGPT but aims to generate text that closely mirrors human conversation.

While the GPT series has significantly succeeded in numerous NLP tasks, it faces several challenges. Some of these problems can be traced back to the training methodologies implemented by the model.
For instance, while the usage of a large corpus has benefited the GPT series, it has also led to the absorption of inherent biases from the corpus, causing the model to exhibit low consistency and a higher propensity of generating artificial-looking contexts that might seem correct.
Moreover, the supervised learning approach implemented by InstructGPT and ChatGPT isn’t immune to bias, as the varying backgrounds of the labelers could influence the model’s overall behavior, rendering it difficult to detect and mitigate. A well-known example of this is seen in Behavior Cloning. To simplify, let’s consider a straightforward example to illustrate this phenomenon.

Let’s assume that the LLM can only process a very limited number of tokens. In this scenario, even though the labeler provides a conclusion along with the corresponding evidence, due to the limited token capacity, the LLM only ‘sees’ a strong conclusion without any supporting evidence. To mimic the behavior of the labeler, the LLM will begin to fabricate evidence to substantiate the conclusion. This is a simple example, but it vividly illustrates how the LLM can be influenced by the bias of the labeler. For more details, please refer to Behavior Cloning.
combination of LLMs and KGs
How can KGs help LLMs?
It is evident that high-quality knowledge graphs (KGs) can assist LLMs in achieving better accuracy, consistency, and explainability. However, how can this idea be implemented? In this section, we will discuss two methods: KGs as training data and KGs as part of the prompt.
KGs as training data
A straightforward approach involves utilizing KGs as training data. However, being a language model, the GPT series only accepts text as input, thereby necessitating the conversion of KGs into text format. A notable work in this area is TekGen proposed by Google. The underlying mechanism of TekGen is depicted in the figure below.
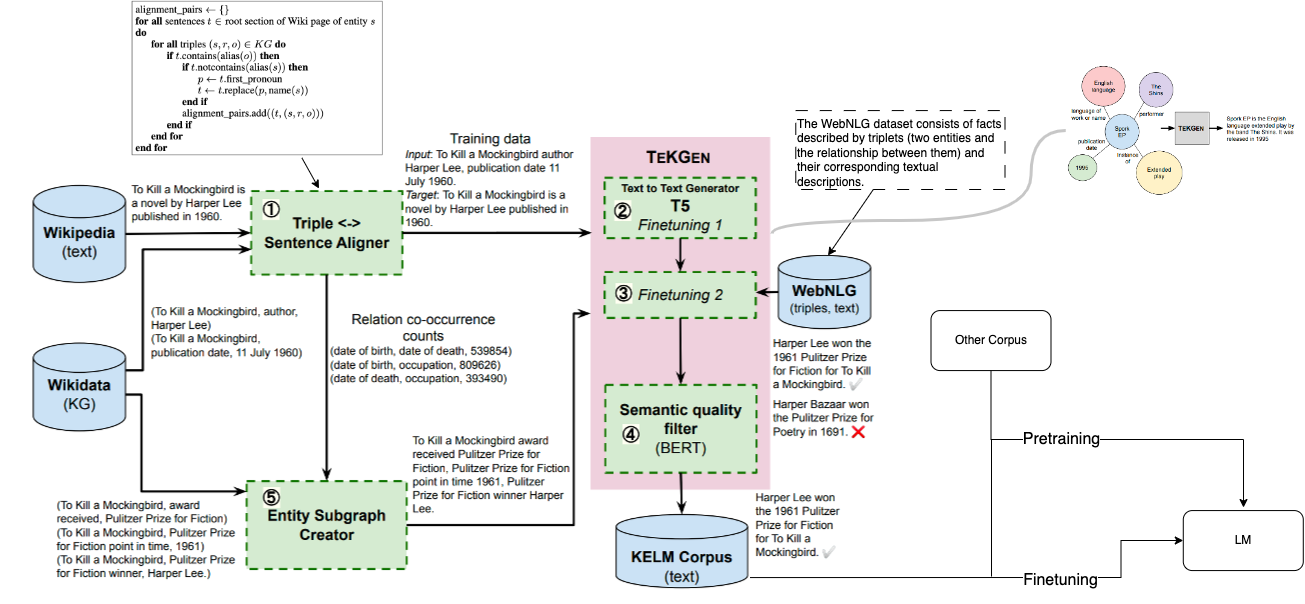
With the help of TekGen, we can convert KGs to text and use them as training data, either at the pre-training stage or during fine-tuning. However, I don’t think this methodology fully leverages the potential of KGs. My reasons are two-fold. First, the scale of KGs is limited. Although KGs are high-quality knowledge sources, their scale is insufficient to significantly change the distribution of the training dataset. Therefore, the impact of this method is limited. Second, this methodology converts the inherent explainability of KGs into a black box. KGs are structured data with high explainability. But after converting them to text, we lose this explainability.
KGs as Part of the Prompt
Another approach is to use KGs as part of the prompt. In other words, we can utilize KGs as a tool for LLMs to generate text by feeding topic-related KGs into the prompt. The working principle of this method is depicted in the figure below.

This methodology gained traction with the publication of Toolformer. The main idea of Toolformer is to tune LLMs to generate API queries. Various tools can be utilized to implement different functions following the queries and return the results to the LLMs. Inspired by this concept, Graph Toolformer implemented a wide range of API templates to assist LLMs in handling graph-related tasks.

The Toolformer framework requires tuning LLMs to generate API queries, a task that may be challenging for many. An alternative approach is to allow LLMs to write SQL queries to interact directly with graph databases. For instance, this project leverages GPT-4 to generate Cypher queries to interact with a Neo4j database containing information about movies. With minimal effort, we can create a chatbot capable of answering questions about movies.
How can LLMs help KGs?
While high-quality knowledge graphs can assist LLMs, constructing such knowledge graphs can be challenging. Therefore, we can also consider the reverse approach: can LLMs help build high-quality knowledge graphs? The answer is yes. In this section, we will discuss two methods: ‘LLMs as a knowledge graph’ and ‘LLMs as a tool to build knowledge graphs’. The central concept is depicted in the figure below.

The most straightforward way to use LLMs to build KGs is to let LLMs act as a knowledge graph. However, the current ability of LLMs is limited (we will discuss this later). For a more practical approach, we can use LLMs as a tool to build KGs. For example, we can use LLMs to extract entities and relations from text. We will discuss these two methods in more detail below.
LLMs as a Knowledge Graph
The first method is to use LLMs as a knowledge graph. As we discussed before, LLMs contain a wealth of knowledge. So, can we use LLMs as a knowledge graph directly? To be more specific, in the last section, we used KGs as part of the prompt to assist LLMs in generating text. In that case, we utilized the knowledge in KGs to enhance the ability of LLMs. However, if the ability of LLMs is strong enough, we can directly use LLMs as a knowledge graph. The overall working principle of this method is depicted in the figure below.

This paper has made a comprehensive discussion about the abilities LLMs should have to act as a knowledge graph, which is summarized in the following figure.

Taking consistency as an example, for LLMs to function as a knowledge graph, they should have the ability to consistently answer questions about the same topic. This consistency can be manifested in several aspects:
- Paraphrase: This involves sentences that convey approximately the same meaning using different words. An LLM-as-KG should provide the same results when queried for the same fact but under different wording.
- Common Sense: Previous work explores the brittleness of LMs and the impact of adding a negation element (e.g. ’not’) to a probe. Specifically, an LM can maintain two contradictory beliefs in its parameters, such as “Birds can fly” and “Birds cannot fly”, showing that they are insensitive to the contextual impacts of negation.
- Multilingual: An LLM-as-KG should provide the same results when queried for the same fact but in a different language.
If you are interested in this topic, you can read the aforementioned paper for more details. It is clear that LLMs still have a long way to go to function as a knowledge graph. However, it is a promising direction to explore.
LLMs as a Tool to Build a Knowledge Graph
Another method is to use LLMs as a tool to build a knowledge graph. This approach is more practical and has been implemented in many projects.
For example, the Knowledge-graph-from-GPT-3 project uses GPT-3 to generate triples from question-answer pairs. The generated triples are then processed using graph embeddings to infer connections and construct a knowledge graph. GPT-3’s role in this project, as shown in the figure below, is primarily for entity extraction.
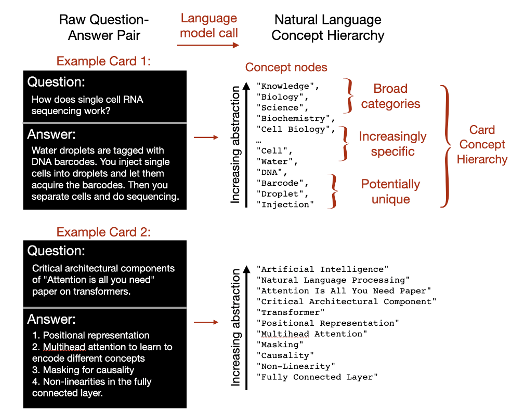
With the advent of chatGPT, LLMs have become even more powerful for entity and relation extraction, thanks to prompt engineering. A Zero-shot method claims that chat-format prompts are more effective than vanilla prompts for Information Extraction. The well-known package, Langchain, also implements related functions to extract triples from plain text. I was genuinely amazed by the power of Prompt Engineering when I used LangChain, and I recommend trying this package to unlock the potential of LLMs. Building on LangChain, Kor implements a pipeline to extract entities and relations from plain text. All we need to do is provide specific descriptions of entities and relations.

With the workflow outlined above, we can extract triples from plain text and create or modify a knowledge graph. There are several online implementations that allow you to experiment with this process. For instance, GraphGPT is a demo that extracts triples from plain text. After providing your OpenAI API key, you can start experimenting. The following figure shows the result of extracting triples from a sentence.